







[dpla] Amsterdam, Monday morning session
Jon Palfrey: The DPLA is ambitious and in the early stages. We are just getting our ideas and our team together. We are here to listen. And we aspire to connect across the ocean. In the U.S. we haven’t coordinate our metadata efforts well enough.
One of the core principals is interoperability across systems and nations. It also means interoperability at the human and institutional layers. “We should start with the presumption of a high level of interoperability.” We should start with that as a premise “in our dna.”
|
NOTE: Live-blogging. Getting things wrong. Missing points. Omitting key information. Introducing artificial choppiness. Over-emphasizing small matters. Paraphrasing badly. Not running a spellpchecker. Mangling other people’s ideas and words. You are warned, people. |
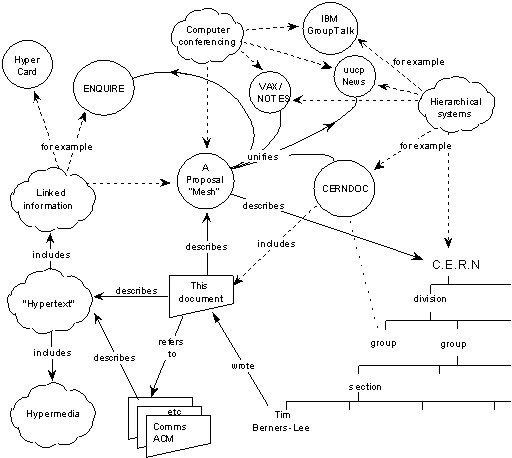
Dan Brickley is asked to give us an on-the-spot, impromptu history of linked data. He begins with a diagram from Tim Berners Lee w3c.org/history/1989 that showed the utility of a cloud of linked documents and things. [It is the typed links of Enquire blown out to a web of info.] At an early Web conf in 1994 TBL suggested a dynamic of linked documents and of linked things. One could then ask questions of this network: What systems depend on this device? Where is the doc being used? RDF (1997) lets you answer such questions. It grew out of PICS, an early attempt to classify and rate Web objects. Research funding arrived around 2000. TBL introduced the semantic web. Conferences and journals emerged, frustrating hackers who thought RDF was about solving problems. The Semantic Web people seemed to like complex “knowledge representation” systems. The RDF folks were more like “Just put the data on the Web.”
For example, FOAF (friend of a friend) identified people by pointing to various aspects of the person. TBL in 2005 critiqued that, saying tht should instead point to URI’s. So, to refer to a person, you’d put int a URL to info that talk about them. Librarians were used to using URL’s as pointers, not information. TBL further said that the URI should point to more URI’s, e.g., the URL for the school that the person went to. TBLs 4 rules: You URIs for names for things. 2. Make sure http can fetch them. 3. Make sure what you fetch is machine-frineldy. 4. Make sure the links use URIs. This spreads the work of describing a resource around the Web.
Linked Data often takes a database-centric view of the world; building useful databases out of swarms of linked data.
Q: [me] What about ontologies?
A: When RDF began, an RDF scema defined the pieces and their relationships. OWL and ontologies let you make some additional useful restrictions. Linked data people tend to care about particularities. So, how do you get interoperability? You can do it. But the machine stuff isn;t subtle enough to be able to solve all these complex problems.
Europeana
Paul Keller says that copyright is supposed to protect works, but not the data they express. Cultural heritage orgs generally don’t have copyright on their material, but they insist on copyrighting the metadata they’ve generated. Paul is encouraging them to release their metadata into the public domain. The orgs are all about minimizing risk. Paul thinks the risks are not the point. They ought to just go ahead an establish themselvs as the preservers and sources of historical content. But the boards tend to be conservatve and risk-adverse.
Q: US law allows copyright of the arrangement of public domain content. And do any of the collecting societies assert copyright?
A: The OCLC operates the same way in Europe. There’s a proposed agreement that would authorize the aggregators to provide their aggregators under a CC0 public domain license.
Q: Some organizations that limit images to low-resolution to avoid copyright issues. Can you do the same for data?
A: A high res description has lots of information about how it deroved tje infro.
Antoine Isaac (Vrje Universteit Amsterdam) has worked on the data model for Europeana .EDE (Europeana Semantic Elements) are like a Dublin Core for objects: a lowest common denominator. They are looking at a richer model, Europeana Data Model. Problems: Ingesting refs to digitized material, ingesting descriptive metadata from man institutions, build generic services to enhance access top objects.
Fine-grained data: Merging multiple records can lead to self-contradiction. Have to remember who data came from which source. Must support objects that are composed of other objects. Support for contextual resources (e.g., descriptions of persons, objects, etc.) including concepts, at various levels of detail.
Europeana is aiming at interoperability through links (connecting resources), through semantics (complex data semantically interoperable with simpler objects), and through re-use of vocabularies (e.g., OAI-ORE, Dubliin Core, SKOS, etc.) They create a proxy object for the actual object, so they don’t have to mix with the data that the provider is providing. (Antoin stresses that the work on the data model has been highly collaborative.)
Q: Do we end up with what we have in looking up flight info? Or can we have single search?
A: Most important we’re working on the back end, not yet working on the front end.
The Lin
Q: Will you provide resolution services, providing all the identiiers that might go with an object?
A: Yes.
Q: Stefan Gradmann also points to the TBL diagram with typed linked. Linked Data extends this in type (RDF) and scope. RDF triples (subject-predicate-object). He refers to TBL’s four rules. Stefan says we may be at the point of having too many triples. The LinkingOpenData group wants to build a data commons. (see Tom Heath and Chris Bizer.) It is currently discussing how to switch from volume aggregation to quality. Quality is about “matching, mapping, and referring things to each other.”
The LOD project is different. It’s a large-scale integration project, running through Aug 2014. It’s building technology around the cloud of linked open data. It includes the Comprehensive Knowledge Archive Network (CKAM), DBpedia extraction from Wikipedia.
Would linked data work if it were not open? Technically, it’s feasible. But it’s very expensive, since you have to authorize the de-referencing of URIs. Or you could do it behind a proxy, so you use the work of others but do not contribute. Europeana is going for opennness, under CCO: http://bit.ly/fe637P You cannot control how open data is used, you can’t make money from it, and you need attractive services to built on top of it, including commercial services. Europeana does not exclude commercial reuse of linked open data. Finally, we need to be able to articulate what the value of this linked data is.
Q: How do we keep links from rotting?
A: The Web doesn’t understand versioning. One option is to use the ORE resource maps, versioning aggregations.
Q: Some curators do not want to make sketchy metadata public.
A: The metadata ought to state that the metadata is sketchy, and ask the user to improve it. We need to track the meta-metadata.
Stefan: We only provide top-level classifications and encourage providers to add the more fine-grained.
Q: How do we establish the links among the bubbles? Most are linked to DBpedia, not to one another?
A: You can link on schema or instance level. The work doesn’t have to be done solely by Europeana.
Q: The World Intellectual Property Organization is meeting in the fall. A library federation is proposing an ambitious international policy on copyright. Perhaps there should be a declaration of a right to open metadata.
A: There are database rights in Europe, but generally not outside of it. CCO would normalize the situation. We think you don’t have to require attribution and provenance because norms will handle that, and requiring it would slow development.
Q: You are not specifying below a high level of classification. Does that then fragment the data?
A: We allow our partners to come together with shared profiles. And, yes, we get some fragmentation. Or, we get diversity that corresponds to diversity in the real world. We can share contextualization policies: which are our primary goals when contextualizing goals, e.g., we use VIAF rather than FOAF when contextualizing a person. Sort of a folksonomic process: a contributor will see that others have used a particular vocabulary.
Q: Persistence. How about if you didn’t have a central portal and made the data available to individual partners. E.g., I’m surprised that Europeana’s data is not available through a data dump.
A: The license rights prevent us from providing the data dump. One interesting direction: move forward from the identifiers the institutions already have. Institutions usually have persistent identifiers, even though they’re particular to that institution. It’d be good to leverage them.
A: Europeana started before linked open data was prominent. Initially it was an attempt to build a very big silo. Now we try to link up with the LoD cloud. Perhaps we should be thinking of it as a cloud of distributed collections linked together by linked data.
Q: We provide bibliographic data to Europeana. I don’t see attribution as a barrier. We’d like to some attribution of our contribution. As Europeana bundles it, how does that get maintained?
A: Europeana is structurally required to provide attribution of all the contributors in the chain.
Q: Attribution even share-alike can be very attractive for people providing data into the commons. Linux, Open Street Map, and Wikipedia all have share-alike.
A: The immediate question is non-commercial allowed or not.
Q: Suppose a library wanted to make its metadata openly available?
A: SECAN.


{kind=link}